728x90
반응형
다음과 같이 40300 데이터가 빠진 numpy 배열 데이터가 있습니다.
import numpy as np
# 과학적 표기법 대신 소수점 6자리까지 나타낸다.
np.set_printoptions(precision=6, suppress=True)
lst = [
[20230202,40600, 1.42]
,[20230202,40500, 1.42]
,[20230202,40400, 1.42]
# ,[20230202'40300, 1.42]
,[20230202,40200, 1.42]
,[20230202,40100, 1.42]
,[20230202,40000, 1.42]
]
data = np.array(lst)
print(type(data), data.shape)
print(data)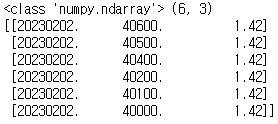
빠진 데이터를 추가하기 위해서 다음과 같이 만듬
new_lst = []
idx = 0
n_start = int(data[0][1]) # 원 데이터가 인덱스로 보면 높은 수가 인덱스0이 있고, 낮은수가 인덱스가 크게 되어 있음
n_end = int(data[len(data)-1][1]) - 100 # -100은 range 할때 end-1까지 나오기 때문에 모두 나오게 하기위해 -100 처리 함.
for n in range(n_start, n_end, -100): # 높른 수부터 낮은수가 나오도록 step을 -100 으로 함. 이게 기준 수가 됨.
old_n = int(data[idx][1]) # [20230202,40600,1.42]와 같은 구조에서 인덱스 1 이 찾는 값임
if n == old_n: # for 문의 range에 의해서 만들어진 기준 수 n과 비교. 같으면 기존 data에 있는 값
d_date = int(data[idx].tolist()[0]) # 기존 data에서 값 가져옴. 아래 append에서 모두 처리 할 수 있으나 설명을 위해 풀어 씀
d_n = int(data[idx].tolist()[1])
d_v = float(data[idx].tolist()[2])
new_lst.append([d_date, d_n, d_v]) # 새로운 리스트 변수에 추가
idx += 1 # 기존 데이터인 data 배열의 인덱스 값을 증가 시킴. 아래 빠진 데이터 추가시는 이 코드가 없음
else: # for 문의 range에 의해서 만들어진 기준 수 n과 비교헤서 같이 않으면 기존 data에 없는 수임.
new_date = 20230202 # 기존 값이 동일하는 동일하게 사용
new_n = n # range에서 의해서 만들어진 n 을 사용. 빠진 n 값임
new_value = 1.41 # 원하는 값을 넣으면 됨
new_lst.append([new_date, new_n, new_value]) # 새로운 리스트 변수에 추가
new_data = np.array(new_lst) # 일반 리스트를 numpy 배열로 만듬
728x90
반응형
'프로그램' 카테고리의 다른 글
| [파이썬] 문제 : 특정 라인 중 짝수만 출력 (0) | 2023.02.15 |
|---|---|
| [파이썬] 문제 : 여러 txt 파일 합치기 (0) | 2023.02.15 |
| [파이썬] 문제 : 딕셔너리 과목 합계와 평균 (1) | 2023.02.04 |
| [파이썬] pandas DataFrame의 인덱스 Header 위에 문자 추가 (0) | 2023.02.03 |
| [파이썬] 문제 : pandas DataFrame pivot(Matrix로 보기) (0) | 2023.02.02 |


댓글